SPEI
# gma.climet.Index.SPEI(PRE, PET, Axis = None, Scale = 1, Periodicity = 12, Distribution = 'LogLogistic', FitMethod = 'LMoment', Calibration = None)1.0.10 +
功能:【标准化降水蒸散指数】。计算标准化降水蒸散指数(Standardized Precipitation Evapotranspiration Index)。
参数:
PRE: array。降水量(mm)。
PET: array。潜在蒸散量(mm)。
可选参数:
Axis = int。计算轴。如果不设置(None),多维数据会将所有数据展开到一维计算。
Scale = int。时间尺度。默认为 1。例如:1月、3月或其他。
Periodicity = int。周期。默认为 12。
关于周期
周期定义了参与拟合数据的分组方式,例如:
输入月数据,Periodicity = 12 时,每个月份(共 12 组数据)之间互不干扰,独立拟合,更适合针对月份独立分析;
输入月数据,Periodicity = 1 时,所有月份(共 1 组)同时参与拟合,相互影响,更适合分析月份之间的差异;
Distribution = str 1.1.1 +。用于内部拟合/变换计算的分布类型。默认为 LogLogistic。
支持的分布类型
'Gamma':伽马分布;
'LogLogistic':对数逻辑斯蒂分布;
'Pearson3':皮尔逊 III 分布。
FitMethod = str 2.0.4 +。用于内部拟合/变换计算的参数估计方法。默认为 LMoment。
支持的分布类型
'MLE':最大似然估计;
'LMoment':L-矩估计(PWD,概率加权矩);
'LMoment2':L-矩估计。
Calibration = list||slice||None2.0.4 +。参与内部参数拟合运算数据的周期。默认(None)为全部数据。
例如
全部数据:Calibration = None
第1~10个周期:Calibration = [0, 10]
在第1~50个周期中,每隔 2 周期选一组数据:Calibration = slice(0, 50, 2)
返回:array。
参考文献:
Vicente-Serrano S M , S Beguería, JI López-Moreno. A Multiscalar Drought Index Sensitive to Global Warming: The Standardized Precipitation Evapotranspiration Index[J]. Journal of Climate, 2010, 23(7):1696-1718.
示例:
from gma import climet
基于 Excel 表数据(下载 示例数据)
from gma import io
ELSXLayer = io.ReadVector('PRE_ET0.xlsx')
Data = ELSXLayer.ToDataFrame()
PRE = Data['PRE'].values
ET0 = Data['ET0'].values
# 分别计算1个月、3个月、6个月、12个月、24个月、60个月尺度的 SPEI 指数
SPEI1 = climet.Index.SPEI(PRE, ET0)
SPEI3 = climet.Index.SPEI(PRE, ET0, Scale = 3)
SPEI6 = climet.Index.SPEI(PRE, ET0, Scale = 6)
SPEI12 = climet.Index.SPEI(PRE, ET0, Scale = 12)
SPEI24 = climet.Index.SPEI(PRE, ET0, Scale = 24)
SPEI60 = climet.Index.SPEI(PRE, ET0, Scale = 60)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
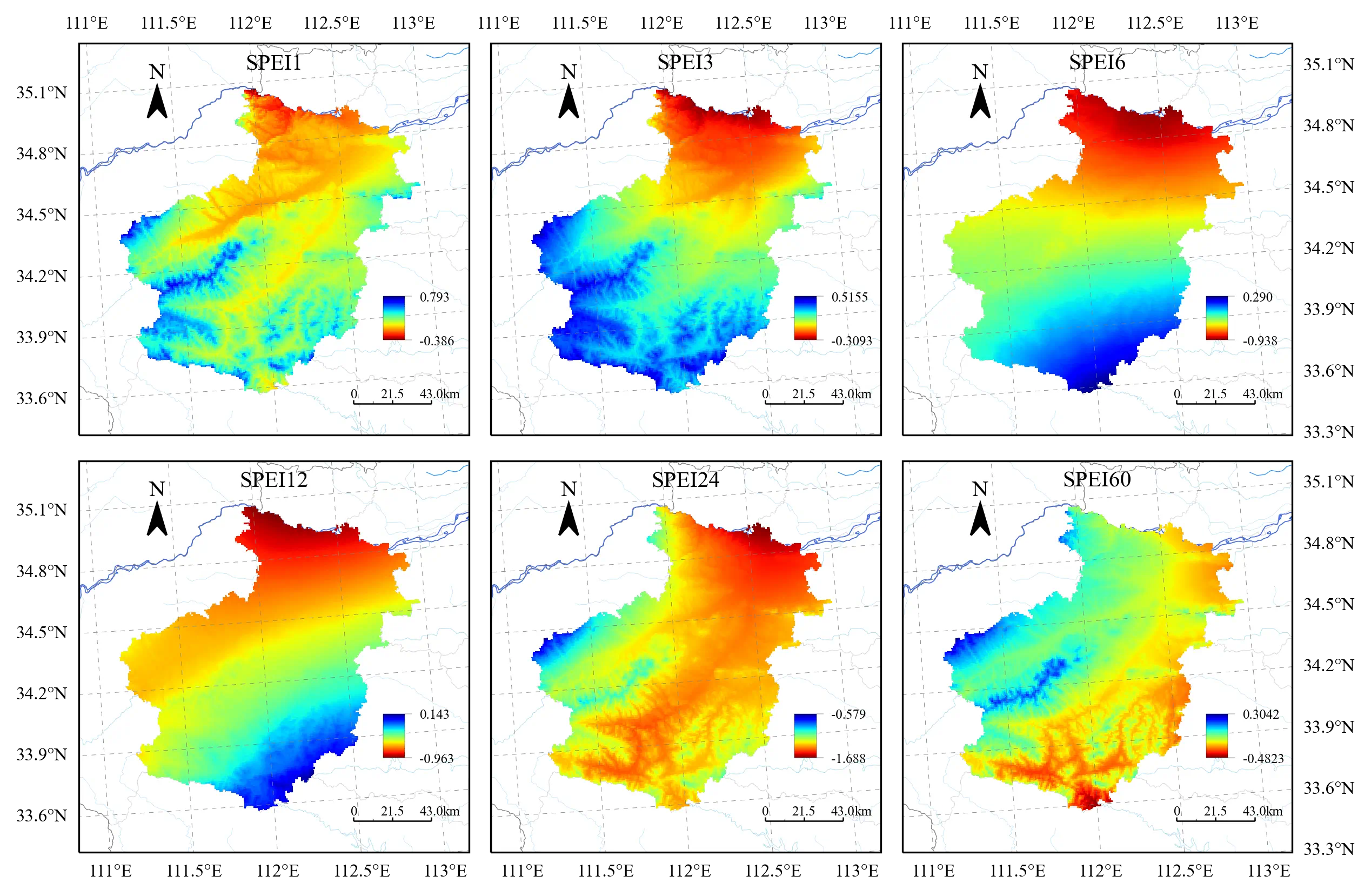
不同尺度 SPEI 结果

基于栅格数据(下载 示例数据)
import numpy as np
from gma import io
# 读取数据集
PRESet = io.ReadRaster('PRE_Luoyang_1981-2020.tif')
ET0Set = io.ReadRaster('ET0_Luoyang_1981-2020.tif')
PRE = PRESet.ToArray()
ET0 = ET0Set.ToArray()
# 读取的数据为三维数据(波段,行,列),第一维为时间序列(月数据)。因此按照轴 0 来计算
SPEI1 = climet.Index.SPEI(PRE, ET0, Axis = 0)
SPEI3 = climet.Index.SPEI(PRE, ET0, Axis = 0, Scale = 3)
SPEI6 = climet.Index.SPEI(PRE, ET0, Axis = 0, Scale = 6)
SPEI12 = climet.Index.SPEI(PRE, ET0, Axis = 0, Scale = 12)
SPEI24 = climet.Index.SPEI(PRE, ET0, Axis = 0, Scale = 24)
SPEI60 = climet.Index.SPEI(PRE, ET0, Axis = 0, Scale = 60)
# 存储计算结果
S = [1,3,6,12,24,60]
for i in S:
# 保存所有结果中的非全 nan 波段。即:去除时间尺度累积时序列前无效的波段。
io.SaveArrayAsRaster(eval(f'SPEI{i}')[i-1:],
fr'.\1981-2020_SPEI{i}.tif',
Projection = PRESet.Projection,
Transform = PRESet.GeoTransform,
DataType = 'Float32',
NoData = np.nan)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
最后一个月(2020年12月)计算结果